MILAN BAR ASSOCIATION: MRS. SIMONA LAVAGNINI WILL SPEAK AT THE “INTELLECTUAL PROPERTY AND ANTITRUST COMMISSION” CONFERENCE ON 18 APRIL 2023
17/04/2023
On 18 April, Mrs. Simona Lavagnini will intervene as speaker – as well as President of AIPPI Gruppo Italiano – at the Conference “Intellectual Property and Antitrust Commission”, organised by the Milan Bar Association at the Aula Magna of the Palazzo di Giustizia from 2.30 p.m. to 5.30 p.m.
During the Conference, the establishment of the Intellectual Property and Antitrust Commission – of which Mrs. Simona Lavagnini, founding partner of LGV Avvocati, will be a member – will be announced. During her speech, Mrs. Lavagnini will also discuss the topic “Intellectual Property Licences and Social Networks”.
The event is free of charge, has been organised by the Milan Bar Association as part of the continuing legal education programme for lawyers and allows the award of no. 3 training credits.
Registrations must be made online on the dedicated portal Sfera: https://sfera.sferabit.com/servizi/accesso_albosfera.php
LGV AVVOCATI is a recommended IP firm: #TheLegal500 rankings for 2023 are out!
13/04/2023
Another year for LGV Avvocati among the best law firms in Italy in the areas of “Intellectual Property: Copyright” (TIER 2) and “Intellectual Property” (TIER 3), according to the 2023 #TheLegal500 rankings.
Mrs. Simona Lavagnini has also been awarded as “Leading Individual”, together with our “Rising Star”, Mr. Alessandro Bura.
Ranking Chambers 2023
17/03/2023
We are pleased to announce that Chambers (2023) has ranked LGV Avvocati in Band 3 as Intellectual Property Practice. Our founding partner Simona Lavagnini is ranked in Band 1 for Copyright. Our founding partner Luigi Goglia is ranked in Band 4. Last but not the least, our Senior Associate Alessandro Bura has been marked as “Associate to watch”.
The ranking is available at: https://chambers.com/department/lgv-avvocati-intellectual-property-europe-7:34:117:1:180964
ARTIFICIAL INTELLIGENCE AND CREATIVE CHARACTER: US COPYRIGHT OFFICE LAYS DOWN RESTRICTIVE RULES
13/03/2023
On 25 February 2023, the United States Copyright Office (USCO) issued a landmark decision concerning the protectability by copyright of results achieved by means of AI, concluding that this protection cannot be granted to material created by AI in a non-predictive manner, i.e. not controllable in its expressive form by the user/author (https://www.riaa.com/wp-content/uploads/2023/02/AI-COPYRIGHT-decision.pdf). In reaching its decision, the USCO analyses in great depth and detail the requirements for the recognition of author protection, expressing extremely interesting assessments of the notion of “idea” (not protectable) and “expressive form” (protectable), the scope of which may well go beyond the boundaries of the AI, and instead concern the entire copyright system.
To better understand the USCO’s decision, it is important to keep in mind the type of work of art whose protection was claimed (entitled “Zarya of the Dawn”), as well as – above all – the method of operation of the AI used in its creation. ‘Zarya of the Dawn’ is a comic book, consisting of eighteen pages, including a cover page. The cover features a picture of a young woman, as well as the title of the work and the words ‘Kashtanova’ and ‘Mid Mid’ (referring respectively to the name of the designer who intended to record the work, Kristina Kashtanova, and to the name of the AI she used, i.e. Midjourney). The other pages of which the work was composed consisted of mixed textual and visual material (in other words, graphic images accompanied by captions: see below the images taken from the USCO decision).
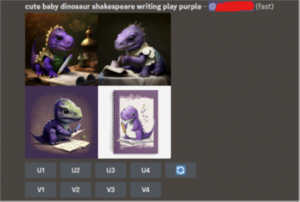
According to the applicant’s own statement, all the images used in the work were created by Kashtanova through the use of Midjourney technology, which consists of a subscription service that allows users to pay to generate images, with subscription plans corresponding to the time used to generate the images. In concrete terms, the user – once subscribed to the service – generates a text message expressing the requirements of the image to be generated by the AI. It is also possible for users to indicate a URL of one or more images to influence the output generated by the AI, or to set parameters that provide functional indications. Following the prompt entered by the user, Midjourney generates four images in response, which – by means of a grid and buttons – can be managed in various ways, e.g. to obtain a higher-resolution version of an image, to create new variants or even to generate four new images from scratch. According to the examples provided by the USCO, by entering the command “/imagine cute baby dinosaur shakespeare writing play purple” the AI provides four different images, in any case referring to puppies, dinosaurs, the color purple, and Shakespeare. However, the images have different (expressive) characteristics, as the puppy has specific shapes, colors, proportions in each of the images (see image from the USCO decision below):
In this context, the USCO particularly emphasizes the circumstance that the instructions given by the user to the AI do not concern the realization of a particular expressive result, but simply indicate in broad terms the objective to be achieved. Moreover, the way Midjourney operates is peculiar in that it actually converts the words and phrases contained in the user prompt “into smaller pieces, called tokens, that can be compared to its training data and then used to generate an image.” The generation involves Midjourney starting with “a field of visual noise, like television static, [used] as a starting point to generate the initial image grids” and then using an algorithm to transform them into human-recognizable images, according to its own training data and matching them with the user’s specified features. The latter, however, does not control the creation process by the AI, because it is not possible to predict what the images actually generated by Midjourney will be, in terms of expressive elements. In practice, of course the image will be that of a baby dinosaur writing a play, as Shakespeare might have done, where the visual connotation is that of purple; but no one can determine whether the baby will be tall or short, thin or strong, smiling or worried (or expressionless), with sweet or threatening shapes, etc. It is therefore a completely different way of working than the typical creative way of working of the author/artist, even when the latter uses an instrument, since in all these cases it is the author/artist who controls the instrument itself, and who knows which elements to use to realize the work they have in mind. In the specific case of the work “Zarya of the Dawn”, the USCO therefore concludes by limiting the copyright registration to the textual parts of the work itself (the captions commenting on the images), and to the activity of selecting and arranging the images used for the composition of the book, denying protection to the individual images. In the case of the texts, the USCO’s decision appears to be obligatory: the designer had in fact affirmed (and was not questioned by anyone) that the texts of the captions had been created directly by herself. With regard to the selection of the images, the USCO accepted the designer’s claims that her creative process had consisted of generating a series of images by means of AI, which had then been carefully selected and organized by her in order to create the whole constituted by the story told in the comic strip. In both cases, the activity carried out by the designer is considered sufficient by the USCO to confer copyright protection, since there is creativity (albeit minimal), and the author is a natural person. On the other hand, protection is denied to individual images created by the designer through interaction with AI. According to the USCO, in fact, although the designer claimed to have ‘guided’ the structure and content of each image, the process described made it clear that it was the AI – and not the designer – that gave rise to the ‘traditional elements of authorship’ of the images. The fact that the designer had entered the prompts to obtain the images, and then had chosen one or more of them for further development by modifying the prompt or other inputs provided by the AI did not constitute for the Office enough evidence of sufficient creativity of the work. This is because the process envisaged by the AI is a series of trial and error until, in a random way, the image generated independently by the algorithm comes close to the designer’s original vision. According to the USCO, therefore, rather than a tool that Ms Kashtanova controlled and guided to achieve the desired image, Midjourney generates images in an unpredictable manner. Accordingly, the users of Midjourney are not the ‘authors’, for copyright purposes, of the images generated by the technology. As the Supreme Court has explained, the ‘author’ of a copyrighted work is the person ‘who actually formed the image’, the person acting in an ‘inventive mind’ capacity. The person who provides textual suggestions to Midjourney does not ‘actually form’ the generated images and is not the ‘mind’.
In dealing with the specific issue of textual prompts by the designer to the AI, in order to deny protection, the USCO addresses the issue of the distinction between the ‘idea’ and the ‘expression’ in the intellectual work, reaching in my opinion innovative results of particular interest that extend beyond the scope of the AI, to invest the entire perimeter of intellectual works protected by copyright. Indeed, the Office considers that the prompts given by the designer to the AI function more as suggestions than as orders. In this (the comparison is by the USCO) they are similar to the situation where a client engages an artist to create an image by giving the latter general indications as to the result that should be achieved. In these cases, the author would be the visual artist who received the instructions and independently determined the best way to express them. Thus, the commissioner would provide the (unprotectable) idea, while it is the visual artist who generates the expressive form of the work, and thus receives copyright protection. In concrete terms, the artist would carry out the activity that in the specific case considered by the USCO in its decision of 25 February 2023 is that carried out by the AI, which however – not being human – cannot aspire to the status of author and therefore remains unprotected (as for the output, since the technological system of which the AI consists is well protectable with patents or secrecy). Interestingly, a similar issue was also recently addressed by the Court of Paris, in the case that pitted the well-known visual artist Maurizio Cattelan and his former collaborator Daniel Druet against each other (Court of Paris, judgment of 8 July 2022). Druet is the craftsman that Cattelan used to create some well-known works, such as the ‘Ninth Hour’ (a wax sculpture depicting Pope John Paul II on the ground, struck by a meteorite). Druet asserted in court that he was the co-author of Cattelan’s works, because the latter had only given him vague instructions, and moreover had publicly stated that he was unable to draw, paint or sculpt. According to Druet, therefore, the concrete expressive realization of the work of art was mainly attributable to him. In the proceedings, Cattelan’s defense counsel had, in particular, argued that the realization of the intellectual work is secondary to its conception, particularly in the field of ‘conceptual art’, in which artists often imagine their works but do not create them themselves. In this particular case, the Court – also for procedural reasons – denied Druet’s application, considering that Cattelan had provided sufficiently specific indications for the location of his works (in particular, choice of building and size of the rooms to suit the character of the work, direction of gaze, lighting, destruction of a glass roof or parquet floor to make the installation more realistic and suggestive). However, it did not pronounce ex professo on the main issue, i.e. what activities and choices a person has to make in order to qualify as an author, when they use a third party, or an instrument (including AI), to realize the work of genius. Applying the considerations made by the USCO (and also following the tendency indicated by the decision of the Paris Court in the Cattelan case), the thesis put forward by Cattelan’s lawyer should be refuted. Indeed, it is not enough, even in the field of conceptual art, to merely “conceive” a work, or – in other words “have the creative idea”. Instead, it is necessary to intervene in the concrete expressive choices, establishing the specific characteristics that the work must have, so that – if it is a visual work – one must clearly establish what its dimensions, shapes, proportions, placement, colors, materials used and various components, and so on, must be.
Simona Lavagnini
CHATBOTS AND JOURNALISTIC PUBLICATIONS
17/02/2023
Could the development of chatbots have a negative impact on the newspaper industry? Many players are beginning to wonder, after recent announcements by some market players that chatbots would be integrated into search engines that could provide the user with a service to remix and process content found on the web.
Could the development of chatbots have a negative impact on the newspaper industry? Many players are beginning to wonder, after recent announcements by some market players that chatbots would be integrated into search engines that could provide the user with a service to remix and process content found on the web. In other words, the user would be able to enter a search string into the search engine, just as today, but instead of simply getting a list of websites that might be interesting to visit, as relevant to the content being searched, the user could directly get a summary of the content itself, which could dispense him or her from accessing and reading the original content. From the users’ point of view, this is undoubtedly an efficient solution, because it could enable them to acquire summary answers to their information searches very quickly, without having to visit the websites where the original content is hosted. At the same time, those interested to know in greater depth could always go beyond the summary by accessing and viewing all the original materials. From the point of view of the owners of the websites on which the original content is hosted, however, the innovation posed by chatbots could create a not insignificant problem, since it would drastically decrease user traffic on the sites themselves, with the natural consequence of making them less attractive to the advertising investments that today support much of the income of those operating in this sector. Then there would also be the additional problem of the potential negative effect of this innovation on the way of calculating the fair compensation due to publishers of journalistic publications, which online platforms must now pay following the introduction in our legal system of a new related right for online uses of newspaper articles (see Article 43bis Law 633/41, as introduced into national law following the implementation of EU Directive 790/2019 on the Digital Single Market). The rule in question establishes, as is well known, that reproductions of journalistic publications by online platforms are subject to remuneration, unless the parts of the publications used by online platforms are so short, that the network user is nevertheless led to consult the journalistic publication in its entirety. The remuneration that platforms should pay to publishers of journalistic publications has recently been disciplined by the AGCOM regulation on the identification of criteria for determining fair compensation for the online use of publications of a journalistic nature under Article 43bis of Law 633/41 (Resolution 3/23/CONS https://www.agcom.it/documents/10179/29302270/Allegato+25-1-2023/58525b07-198f-46de-93c8-bd7e3a7a162e?version=1.0). One of the criteria for determining the fee is the number of online consultations of the publisher’s journalistic publications on the provider’s services, expressed in terms of views and user interactions and measured in accordance with criteria of methodological correctness, transparency and verifiability. This criterion should be combined with others, such as the publisher’s market relevance, expressed in terms of online audience and surveyed on a periodic basis in an unbiased manner. Also relevant are the number of journalists, the costs of technological and infrastructural investments for the realization of journalistic publications disseminated online and their communication to the public, adherence to codes of conduct, and the publisher’s years of activity, also in relation to the newspaper’s historicity in the national and local spheres. The first criteria now mentioned (i.e., that of the number of online consultations and that of the publisher’s online audience) could be negatively impacted by the operation of the new chatbots, to the extent that the use of chatbots would cause a reduction in the number of views by users of news publications (in fact, users might be satisfied with the chatbot’s summaries). In addition, and for the same reason, there could also be a contraction of publishers’ online audience, which would further negatively affect the criteria for calculating fair compensation. On the other hand, the realization of summaries of the content of journalistic publications by chatbots could constitute a form of exploitation of the same, however subject to the authorization of the rights holders, although the assessment could depend on the system taken into consideration. While in fact this type of exploitation might be covered by “fair use” in the United States, in continental jurisdictions it might not be possible to use the exceptions regime. In Italy, for example, it could be argued that the realization of summaries by chatbots is not allowed (in the absence of a license) either by the exceptions on text & data mining or by the exception on citation and summary. Regarding the first type of exceptions, EU Directive 790/2019 and its subsequent implementation in Italy (current Art. 70ter and 70quater Law 633/41) provided for the introduction of limitations on the exclusive copyrights in favor of certain parties, aimed at allowing access to data, works or other materials available in networks or databases to which users have lawful access, and then to put in place, for their own research purposes, automated techniques for the analysis of large amounts of text, sound, images, data or metadata in digital format with the aim of generating information, including patterns, trends and correlations. The exceptions of text & data mining are first and foremost aimed at research organizations and cultural heritage institutions, which can then carry out both text & data mining operations for research purposes, as well as the communication to the public of the outcomes of the research itself, expressed in new original works. For entities other than research organizations and cultural heritage protection institutes, there is a text & data mining exception, which, however, seems to have a more limited scope: these types of users may in fact carry out reproduction and extraction operations from works or other materials contained in networks or databases to which they have legitimate access, but on condition that the use has not been expressly reserved by the rights holders; furthermore, the rule does not provide anything regarding the reuse and therefore the communication to the public of the results, which would therefore not seem to be covered by the exception. The question then arises as to the lawfulness of the use of protected data and works by artificial intelligence systems not developed by pure research organizations. In such cases, AI will certainly be able to process materials in the public domain or otherwise not protected by exclusive rights. With regard to protected materials, on the other hand, the question may arise as to whether it is necessary to obtain from the rights holders of the works used by the AI an appropriate license permitting use for the purposes of the AI’s own development. In relation to the exceptions concerning quotation and summary (Art. 70 ff. Law 633/41), under Italian law these forms of exploitation are free if made for the use of criticism and discussion, within the limits justified by these purposes and provided that they do not constitute competition to the economic use of the work. It is precisely this last point that could generate difficulties in the context of artificial intelligence, insofar as it can be demonstrated that the creation and making available to the public of summaries of online publications by chatbots rivals the consultation of original works. Moreover, in any case, the summary, quotation or reproduction must always be accompanied by the mention of the title of the work, the names of the author and publisher, in order to protect moral rights, which should impose additional transparency obligations on chatbots that would make it obvious which source or sources were used for the realization of the summary. Finally, it should not be forgotten that our copyright law provides in Article 101 a competitive type of protection for information and news, according to which the reproduction of information and news is lawful as long as it is not carried out with the use of acts contrary to honest practices in journalistic matters and as long as the source is cited. However, acts of unauthorized reproduction or broadcasting of news bulletins of news agencies carried out before 16 hours have elapsed since the bulletin’s issuance or in any case before their publication in a newspaper or periodical that has received a license to do so, as well as acts of systematic reproduction of news, whether published or broadcast, for profit, either by newspapers or other periodicals or by broadcasting companies, are considered unlawful. The rule is rather old, as can be seen from the wording, but still relevant in its objectives, which are to protect the investment of the newspaper publishing industry from parasitic exploitation, especially in the time frame most relevant to the recovery of the investment, that is, the immediacy of the dissemination of the news item. The object of the protection of Article 101 Law 633/41 is not the intellectual work, and its form of expression, but precisely the news, in its information data, assuming that the acquisition, processing and dissemination of the news itself requires entrepreneurial investments, such as the creation and maintenance of a network of journalistic correspondents in the various territories, or the subsidization of investigative journalism, and so on. As has been noted, it is important to make sure that these investments continue to be possible, because independence and plurality of news sources are crucial and the basis of our society. Indeed, according to Article 11 of the Charter of Fundamental Rights of the European Union, everyone has the right to freedom of expression. This right includes freedom of opinion and freedom to receive or impart information or ideas without interference by public authorities and without boundary limits. In addition, the freedom of the media and their pluralism must be respected. In this context, it is important for all stakeholders to strive to find a proper balance of the interests at stake, which involves finding ways of developing an AI that on the one hand offers users increasingly advanced and efficient services, but on the other hand is also able to preserve (and perhaps even revive) the revenues of an important sector such as journalism, without damaging its independence. In this context, those players who are most attentive to the need to develop responsible digital intelligence “by design” could be favored, insofar as they offer consumers an efficient service based on transparency and reliability of sources, as well as adequate remuneration for the latter, where required by law.
Simona Lavagnini
Il sito utilizza cookie tecnici, anche di terze parti. Per maggiori informazioni è possibile consultare l’informativa cookie completa. Chiudendo questo banner, scorrendo questa pagina o cliccando qualunque suo elemento presti il tuo consenso. AcceptRifiutaRead more
Privacy & Cookies Policy
Privacy Overview
This website uses cookies to improve your experience while you navigate through the website. Out of these, the cookies that are categorized as necessary are stored on your browser as they are essential for the working of basic functionalities of the website. We also use third-party cookies that help us analyze and understand how you use this website. These cookies will be stored in your browser only with your consent. You also have the option to opt-out of these cookies. But opting out of some of these cookies may affect your browsing experience.
Necessary cookies are absolutely essential for the website to function properly. This category only includes cookies that ensures basic functionalities and security features of the website. These cookies do not store any personal information.
Any cookies that may not be particularly necessary for the website to function and is used specifically to collect user personal data via analytics, ads, other embedded contents are termed as non-necessary cookies. It is mandatory to procure user consent prior to running these cookies on your website.